Major IT outage affecting banks, airlines, media outlets across the world
(www.abc.net.au)
from rxxrc@lemmy.ml to technology@lemmy.world on 19 Jul 2024 06:23
https://lemmy.ml/post/18154572
from rxxrc@lemmy.ml to technology@lemmy.world on 19 Jul 2024 06:23
https://lemmy.ml/post/18154572
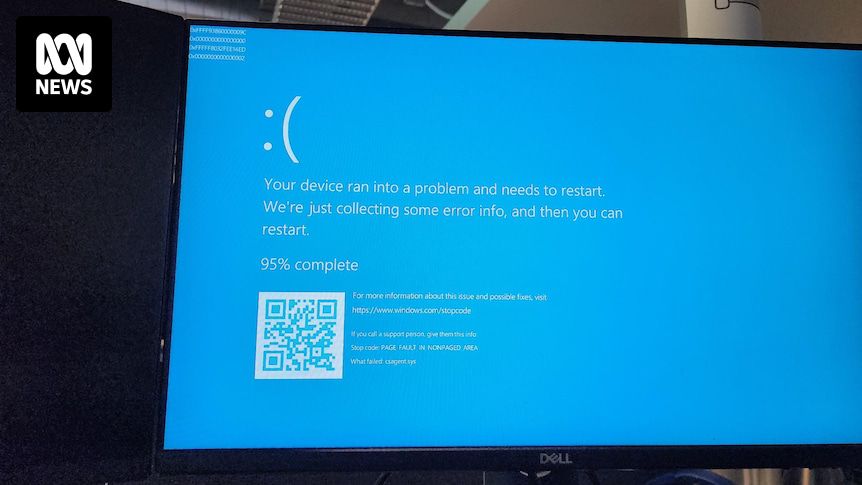
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
threaded - newest
This is the best summary I could come up with:
There are reports of IT outages affecting major institutions in Australia and internationally.
The ABC is experiencing a major network outage, along with several other media outlets.
Crowd-sourced website Downdetector is listing outages for Foxtel, National Australia Bank and Bendigo Bank.
Follow our live blog as we bring you the latest updates.
The original article contains 52 words, the summary contains 52 words. Saved 0%. I’m a bot and I’m open source!
Good bot!
Interesting day
This is going to be a Big Deal for a whole lot of people. I don’t know all the companies and industries that use Crowdstrike but I might guess it will result in airline delays, banking outages, and hospital computer systems failing. Hopefully nobody gets hurt because of it.
Big chunk of New Zealands banks apparently run it, cos 3 of the big ones can’t do credit card transactions right now
It was mayhem at PakNSave a bit ago.
In my experience it’s always mayhem at PakNSave.
If anything, it’s probably calmed P’n’S down a bit…
Bitcoin still up and running perhaps people can use that
Bitcoin Cash maybe. Didn’t they bork Bitcoin (Core) so you have to wait for confirmations in the next block?
Several 911 systems were affected or completely down too
Huh. I guess this explains why the monitor outside of my flight gate tonight started BSoD looping. And may also explain why my flight was delayed by an additional hour and a half…
Xfinity H&I network it down so I can’t watch Star Trek. I get an error msg connection failure. Other channels work though.
My work PC is affected. Nice!
Plot twist: you’re head of IT
Same! Got to log off early 😎
Dammit, hit us at 5pm on Friday in NZ
4:00PM here in Aus. Absolutely perfect for an early Friday knockoff.
Noice!
Yep, stuck at the airport currently. All flights grounded. All major grocery store chains and banks also impacted. Bad day to be a crowdstrike employee!
My flight was canceled. Luckily that was a partner airline. My actual airline rebooked me on a direct flight. Leaves 3 hours later and arrives earlier. Lower carbon footprint. So, except that I’m standing in queue so someone can inspect my documents it’s basically a win for me. 😆
If these affected systems are boot looping, how will they be fixed? Reinstall?
It is possible to edit a folder name in windows drivers. But for IT departments that could be more work than a reimage
Having had to fix >100 machines today, I’m not sure how a reimage would be less work. Restoring from backups maybe, but reimage and reconfig is so painful
Yes, but there are less competent people. The main answer for any slightly complex issue at work is ‘reimage’ - the pancea to solve all problems. And reconfig of personal settings is the users problem.
It’s just one file to delete.
There is a fix people have found which requires manual booting into safe mode and removal of a file causing the BSODs. No clue if/how they are going to implement a fix remotely when the affected machines can’t even boot.
Probably have to go old-skool and actually be at the machine.
Exactly, and super fun when all your systems are remote!!!
It’s not super awful as long as everything is virtual. It’s annoying, but not painful like it would be for physical systems.
Really don’t envy physical/desk side support folks today…
And hope you are not using BitLocker cause then you are screwed since BitLocker is tied to CS.
You just need console access. Which if any of the affected servers are VMs, you’ll have.
Yes, VMs will be more manageable.
Do you have any source on this?
If you have an account you can view the support thread here: …crowdstrike.com/…/Tech-Alert-Windows-crashes-rel…
Workaround Steps:
Boot Windows into Safe Mode or the Windows Recovery Environment
Navigate to the C:\Windows\System32\drivers\CrowdStrike directory
Locate the file matching “C-00000291*.sys”, and delete it.
Boot the host normally.
I can confirm it works after applying it to >100 servers :/
Nice work, friend. 🤝 [back pat]
It seems like it’s in like half of the news stories.
This is a better article. It’s a CrowdStrike issue with an update (security software)
I agree that’s a better article, thanks for sharing
Np man. Thanks for mentioning it.
One possible fix is to delete a particular file while booting in safe mode. But then they’ll need to fix each system manually. My company encrypts the disks as well so it’s going to be a even bigger pain (for them). I’m just happy my weekend started early.
You have ta have access to boot in safe mode too, I guess I can’t on my work pc for example.
What a shitty workaround & might crowd strike burn in hell lol
Enjoy your weekend unless you are in IT
that would only work for like low level people’s laptops. apparently if your role requires a more secure machine you also have to deal with bitlocker whiiiiiiich is tied in with crowdstrike soooooo no dice.
Yeah that would be case in most laptops. So if bitlocker is involved as well what could be the possible fix.
I mean if your IT was smart, IF they were smart, they would have the bitlocker decryptions backed up on like a usb or something. IF you need to access the decryption via microsoft then you’re apparently borked for now.
That would be funny
Yeah, most large orgs have a key server, or back up to AD. If you don’t have that, and no recovery key, you’re fucked and that data is gone.
What if that is running crowdstrike?
I’ll give you one guess.
(That’s why when I was in charge of that stuff at one company, I had that recovery key printed out and kept separately in a lockbox.)
Even if they do, though, if your business isn’t 20 people at 1 location, it’s going to be a giant headache to get people everywhere to fix them all.
oh no doubt, I was telling an old manager of mine today that this “fix” will likely take weeks as he thought it’d just be something they could update. yeah…no. it’s a manual fix for each individul machine. I do not envy anyone working in IT right now.
Here’s the fix: (or rather workaround, released by CrowdStrike) 1)Boot to safe mode/recovery 2)Go to C:\Windows\System32\drivers\CrowdStrike 3)Delete the file matching “C-00000291*.sys” 4)Boot the system normally
It’s disappointing that the fix is so easy to perform and yet it’ll almost certainly keep a lot of infrastructure down for hours because a majority of people seem too scared to try to fix anything on their own machine (or aren’t trusted to so they can’t even if they know how)
It might not even be that. A lot of places have many servers (and even more virtual servers) running crowdstrike. Some places also seem to have it on endpoints too.
That's a lot of machines to manually fix.
That is unfortunate but also leads me to a different question
Why do people like windows server? I’ve had to use it a couple of times for work and although it’s certainly better than just using the desktop windows it’s so heavy compared to running something like Debian
In our case, the fact we were using windows server actually made it a worse experience for customers aswell because the hardware was not up to it (because budget constraints) so it just chugged and slowed down everything making it a terrible experience for everyone involved (not to mention how often it’d have to be rebooted because a service wouldn’t restart)
They also gotta get the fix through a trusted channel and not randomly on the internet. (No offense to the person that gave the info, it’s maybe correct but you never know)
Yeah, and it’s unknown if CS is active after the workaround or not (source: hackernews commentator)
True, but knowing what the fix might be means you can Google it and see what comes back. It was on StackOverflow for example, but at the time of this comment has been taken offline for moderation - whatever that means.
Yeah and a lot of corpo VPNs are gonna be down from this too.
Meh. Even if it bricked crowdstrike instead of helping, you can just restore the file you deleted. A file in that folder can’t brick a windows system.
This sort of fix might not be accessible to a lot of employees who don’t have admin access on their company laptops, and if the laptop can’t be accessed remotely by IT then the options are very limited. Trying to walk a lot of nontechnical users through this over the phone won’t go very well.
Yup, that’s me. We booted into safe mode, tried navigating into the CrowdStrike folder and boom: permission denied.
Half our shit can’t even boot into safe mode because it’s encrypted and we don’t have the keys rofl
If you don’t have the keys, what the hell are you doing? We have bitlocker enabled and we have a way to get the recovery key so it’s not a problem. Just a huge pain in the ass.
I went home lol. Some other poor schmucks are probably gonna reformat the computers.
And people need to travel to remote machines to do this in person
You can do it over the phone. I just did a few dozen this morning and it was relatively easy.
yeah, sometimes that’s just not an option…
Might seem easy to someone with a technical background. But the last thing businesses want to be doing is telling average end users to boot into safe mode and start deleting system files.
If that started happening en masse we would quickly end up with far more problems than we started with. Plenty of users would end up deleting system32 entirely or something else equally damaging.
I do IT for some stores. My team lead briefly suggested having store managers try to do this fix. I HARD vetoed that. That’s only going to do more damage.
Yes but the recovery menu may have been configured to ask for administrative credentials, to prevent unwanted access to the computer, and then fixing the problem would take way longer.
I wouldn’t fix it if it’s not my responsibly at work. What if I mess up and break things further?
When things go wrong, best to just let people do the emergency process.
A driver failure, yeesh. It always sucks to deal with it.
I’m on a bridge still while we wait for Bitlocker recovery keys, so we can actually boot into safemode, but the Bitkocker key server is down as well…
Gonna be a nice test of proper backups and disaster recovery protocols for some organisations
Chaos Monkey test
Man, it sure would suck if you could still get to safe mode from pressing f8. Can you imagine how terrible that’d be?
You hold down Shift while restarting or booting and you get a recovery menu. I don’t know why they changed this behaviour.
That was the dumbest thing to learn this morning.
Not that easy when it’s a fleet of servers in multiple remote data centers. Lots of IT folks will be spending their weekend sitting in data center cages.
don’t rely on one desktop OS too much. diversity is the best.
Dont rely on corpo trash at al.
Annoyingly, my laptop seems to be working perfectly.
That’s the burden when you run Arch, right?
lol he said it’s working
He said it’s working annoyingly.
Reading into the updates some more… I’m starting to think this might just destroy CloudStrike as a company altogether. Between the mountain of lawsuits almost certainly incoming and the total destruction of any public trust in the company, I don’t see how they survive this. Just absolutely catastrophic on all fronts.
If all the computers stuck in boot loop can’t be recovered… yeah, that’s a lot of cost for a lot of businesses. Add to that all the immediate impact of missed flights and who knows what happening at the hospitals. Nightmare scenario if you’re responsible for it.
This sort of thing is exactly why you push updates to groups in stages, not to everything all at once.
Looks like the laptops are able to be recovered with a bit of finagling, so fortunately they haven’t bricked everything.
And yeah staged updates or even just… some testing? Not sure how this one slipped through.
I’d bet my ass this was caused by terrible practices brought on by suits demanding more “efficient” releases.
“Why do we do so much testing before releases? Have we ever had any problems before? We’re wasting so much time that I might not even be able to buy another yacht this year”
At least nothing like this happens in the airline industry
Certainly not! Or other industries for that matter. It’s a good thing executives everywhere aren’t just concentrating on squeezing the maximum amount of money out of their companies and funneling it to themselves and their buddies on the board.
Sure, let’s “rightsize” the company by firing 20% of our workforce (but not management!) and raise prices 30%, and demand that the remaining employees maintain productivity at the level it used to be before we fucked things up. Oh and no raises for the plebs, we can’t afford it. Maybe a pizza party? One slice per employee though.
One of my coworkers, while waiting on hold for 3+ hours with our company’s outsourced helpdesk, noticed after booting into safe mode that the Crowdstrike update had triggered a snapshot that she was able to roll back to and get back on her laptop. So at least that’s a potential solution.
Yeah saw that several steel mills have been bricked by this, that’s months and millions to restart
Got a link? I find it hard to believe that a process like that would stop because of a few windows machines not booting.
That’s the real kicker.
Those machines should be airgapped and no need to run Crowdstrike on them. If the process controller machines of a steel mill are connected to the internet and installing auto updates then there really is no hope for this world.
But daddy microshoft says i gotta connect the system to the internet uwu
No, regulatory auditors have boxes that need checking, regardless of the reality of the technical infrastructure.
There is no unsafer place than isolated network. AV and xdr is not optional in industry/healthcare etc.
I work in an environment where the workstations aren’t on the Internet there’s a separate network, there’s still a need for antivirus and we were hit with bsod yesterday
I don’t know how to tell you this, but…
There are a lot of heavy manufacturing tools that are controlled and have their interface handled by Windows under the hood.
They’re not all networked, and some are super old, but a more modernized facility could easily be using a more modern version of Windows and be networked to have flow of materials, etc more tightly integrated into their systems.
The higher precision your operation, the more useful having much more advanced logs, networked to a central system, becomes in tracking quality control.
Imagine if after the fact, you could track a set of .1% of batches that are failing more often and look at the per second logs of temperature they were at during the process, and see that there’s 1° temperature variance between the 30th to 40th minute that wasn’t experienced by the rest of your batches. (Obviously that’s nonsense because I don’t know anything about the actual process of steel manufacturing. But I do know that there’s a lot of industrial manufacturing tooling that’s an application on top of windows, and the higher precision your output needs to be, the more useful it is to have high quality data every step of the way.)
What lawsuits do you think are going to happen?
They can have all the clauses they like but pulling something like this off requires a certain amount of gross negligence that they can almost certainly be held liable for.
Whatever you say my man. It’s not like they go through very specific SLA conversations and negotiations to cover this or anything like that.
I forgot that only people you have agreements with can sue you. This is why Boeing hasn’t been sued once recently for their own criminal negligence.
👌👍
😔💦🦅🥰🥳
Forget lawsuits, they’re going to be in front of congress for this one
For what? At best it would be a hearing on the challenges of national security with industry.
Agreed, this will probably kill them over the next few years unless they can really magic up something.
They probably don’t get sued - their contracts will have indemnity clauses against exactly this kind of thing, so unless they seriously misrepresented what their product does, this probably isn’t a contract breach.
If you are running crowdstrike, it’s probably because you have some regulatory obligations and an auditor to appease - you aren’t going to be able to just turn it off overnight, but I’m sure there are going to be some pretty awkward meetings when it comes to contract renewals in the next year, and I can’t imagine them seeing much growth
Nah. This has happened with every major corporate antivirus product. Multiple times. And the top IT people advising on purchasing decisions know this.
Yep. This is just uninformed people thinking this doesn’t happen. It’s been happening since av was born. It’s not new and this will not kill CS they’re still king.
At my old shop we still had people giving money to checkpoint and splunk, despite numerous problems and a huge cost, because they had favourites.
Don’t most indemnity clauses have exceptions for gross negligence? Pushing out an update this destructive without it getting caught by any quality control checks sure seems grossly negligent.
Testing in production will do that
Not everyone is fortunate enough to have a seperate testing environment, you know? Manglement has to cut cost somewhere.
Manglement is the good term lmao
I think you’re on the nose, here. I laughed at the headline, but the more I read the more I see how fucked they are. Airlines. Industrial plants. Fucking governments. This one is big in a way that will likely get used as a case study.
The London Stock Exchange went down. They’re fukd.
It’s just amatuer hour across the board. Were they testing in production? no code review or even a peer review? they roll out for a Friday? It’s like basic level start up company “here’s what not to do” type shit that a junior dev fresh out of university would know. It’s like “explain to the project manager with crayons why you shouldn’t do this” type of shit.
It just boggles my mind that if you’re rolling out an update to production that there was clearly no testing. There was no review of code cause experts are saying it was the result of poorly written code.
Regardless if you’re low level security then apparently you can just boot into safe and rename the crowdstrike folder and that should fix it. higher level not so much cause you’re likely on bitlocker which…yeah don’t get me started no that bullshit.
regardless I called out of work today. no point. it’s friday, generally nothing gets done on fridays (cause we know better) and especially today nothing is going to get done.
Can’t; the project manager ate all the crayons
Why is it bad to do on a Friday? Based on your last paragraph, I would have thought Friday is probably the best week day to do it.
Most companies, mine included, try to roll out updates during the middle or start of a week. That way if there are issues the full team is available to address them.
Because if you roll out something to production on a friday whose there to fix it on the Saturday and Sunday if it breaks? Friday is the WORST day of the week to roll anything out. you roll out on Tuesday or Wednesday that way if something breaks you got people around to jump in and fix it.
And hence the term read-only Friday.
Was it not possible for MS to design their safe mode to still “work” when Bitlocker was enabled? Seems strange.
I’m not sure what you’d expect to be able to do in a safe mode with no disk access.
Or someone selected “env2” instead of “env1” (#cattleNotPets names) and tested in prod by mistake.
Look, it’s a gaffe and someone’s fired. But it doesn’t mean fuck ups are endemic.
Don’t we blame MS at least as much? How does MS let an update like this push through their Windows Update system? How does an application update make the whole OS unable to boot? Blue screens on Windows have been around for decades, why don’t we have a better recovery system?
Crowdstrike runs at ring 0, effectively as part of the kernel. Like a device driver. There are no safeguards at that level. Extreme testing and diligence is required, because these are the consequences for getting it wrong. This is entirely on crowdstrike.
This didn’t go through Windows Update. It went through the ctowdstrike software directly.
.
Wow, I didn’t realize CrowdStrike was widespread enough to be a single point of failure for so much infrastructure. Lot of airports and hospitals offline.
Flights grounded in the US.
The System is Down
.
Apparently at work "some servers are experiencing problems". Sadly, none of the ones I need to use :(
.
My favourite thing has been watching sky news (UK) operate without graphics, trailers, adverts or autocue. Back to basics.
I think we’re getting a lot of pictures for !pbsod@lemmy.ohaa.xyz
And subscribed!
Why is no one blaming Microsoft? It’s their non resilient OS that crashed.
Probably because it’s a Crowdstrike issue, they’ve pushed a bad update.
OK, but people aren’t running Crowdstrike OS. They’re running Microsoft Windows.
I think that some responsibility should lie with Microsoft - to create an OS that
I get that there can be unforeseeable bugs, I’m a programmer of over two decades myself. But there are also steps you can take to strengthen your code, and as a Windows user it feels more like their resources are focused on random new shit no one wants instead of on the core stability and reliability of the system.
It seems to be like third party updates have a lot of control/influence over the OS and that’s all well and good, but the equivalent of a “Try and Catch” is what they needed here and yet nothing seems to be in place. The OS just boot loops.
It’s not just Windows, it’s affecting services that people that primarily use other OS’s rely on, like Outlook or Federated login.
In these situations, blame isn’t a thing, because everyone knows that a LSE can happen to anyone at any time. The second you start to throw stones, people will throw them back when something inevitably goes wrong.
While I do fundamentally agree with you, and believe that the correct outcome should be “how do we improve things so that this never happens again”, it’s hard to attach blame to Microsoft when they’re the ones that have to triage and ensure that communication is met.
I reckon it’s hard to attach blame to Microsoft because of the culture of corporate governance and how decisions are made (without experts).
Tech has become a bunch of walled gardens with absolute secrecy over minor nothings. After 1-2 decades of that, we have a generation of professionals who have no idea how anything works and need to sign up for $5 a month phone app / cloud services just to do basic stuff they could normally do on their own on a PC - they just don’t know how or how to put the pieces together due to inexperience / lack of exposure.
Whether it’s corporate or government leadership, the lack of understanding of basics in tech is now a liability. It’s allowed corporations like Microsoft to set their own quality standards without any outside regulation while they are entrusted with vital infrastructure and to provide technical advisory, even though they have a clear vested interest there.
banks wouldn’t use something that black box. just trust me bro wouldn’t be a good pitch
If you trust banks that much, I have very bad news for you.
AFAICT Microsoft is busy placing ads on everything and screen logging user activity instead of making a resilient foundation.
For contrast: I’ve been running Fedora Atomic. I’m sure it is possible to add some kernel mod that completely breaks the system. But if there was a crash on boot, in most situations, I’d be able to roll back to the last working version of everything.
The thought of a local computer being unable to boot because some remote server somewhere is unavailable makes me laugh and sad at the same time.
A remote server that you pay some serious money to that pushes a garbage driver that prevents yours from booting
yeah so you can’t get Chinese government spyware installed.
Not only does it (possibly) prevent booting, but it will also bsod it first so you’ll have to see how lucky you get.
Goddamn I hate crowdstrike. Between this and them fucking up and letting malware back into a system, I have nothing nice to say about them.
It’s bsod on boot
And anything encrypted with bitlocker can’t even go into safe mode to fix it
It doesn’t consistently bsod on boot, about half of affected machines did in our environment, but all of them did experience a bsod while running. A good amount of ours just took the bad update, bsod’d and came back up.
I don’t think that’s what’s happening here. As far as I know it’s an issue with a driver installed on the computers, not with anything trying to reach out to an external server. If that were the case you’d expect it to fail to boot any time you don’t have an Internet connection.
Windows is bad but it’s not that bad yet.
It’s just a fun coincidence that the azure outage was around the same time.
Yep, and it’s harder to fix Windows VMs in Azure that are effected because you can’t boot them into safe mode the same way you can with a physical machine.
Foof. Nightmare fuel.
So, like the UbiSoft umbilical but for OSes.
Edit: name of publisher not developer.
never do updates on a Friday.
yeah someone fucked up here. I mean I know you’re joking but I’ve been in tech for like 20+ years at this point and it was always, always, ALWAYS, drilled into me to never do updates on Friday, never roll anything out to production on Friday. Fridays were generally meant for code reviews, refactoring in test, work on personal projects, raid the company fridge for beer, play CS at the office, whatever just don’t push anything live or update anything.
And especially now the work week has slimmed down where no one works on Friday anymore so you 100% don’t roll anything out, hell it’s getting to the point now where you just don’t roll anything out on a Thursday afternoon.
Excuse me, what now? I didn’t get that memo.
Yeah it’s great :-) 4 10hr shifts and every weekend is a 3 day weekend
Is the 4x10 really worth the extra day off? Tbh I’m not sure it would work very well for me… I find just one 10-hour day to be kinda draining, so doing that 4 times a week every week feels like it might just cancel out any benefits of the extra day off.
I am very used to it so I don’t find it draining. I tried 5x8 once and it felt more like working an extra day than getting more time in the afternoon. If that makes sense. I also start early around 7am, so I am only staying a little later than other people
sorry :( yeah I, at most, do 3 days in the office now. Fridays are a day off and Mondays mostly everyone just works from home if at all. downtown Toronto on Mondays and Fridays is pretty much dead.
I changed jobs because the new management was all “if I can’t look at your ass you don’t work here” and I agreed.
I now work remotely 100% and it’s in the union contract with the 21vacation days and 9x9 compressed time and regular raises. The view out my home office window is partially obscured by a floofy cat and we both like it that way.
I’d work here until I die.
Yep, anything done on Friday can enter the world on a Monday.
I don’t really have any plans most weekends, but I sure as shit don’t plan on spending it fixing Friday’s fuckups.
And honestly, anything that can be done Monday is probably better done on Tuesday. Why start off your week by screwing stuff up?
We have a team policy to never do externally facing updates on Fridays, and we generally avoid Mondays as well unless it’s urgent. Here’s roughly what each day is for:
If things go sideways, we come in on Thu to straighten it out, but that almost never happens.
Actually I was not even joking. I also work in IT and have exactly the same opinion. Friday is for easy stuff!
Never update unless something is broken.
This is fine as long as you politely ask everyone on the Internet to slow down and stop exploiting new vulnerabilities.
I think vulnerabilities found count as “something broken” and chap you replied to simply did not think that far ahead hahah
For real - A cyber security company should basically always be pushing out updates.
Exactly. You don’t know what the vulnerabilities are, but the vendors pushing out updates typically do. So stay on top of updates to limit the attack surface.
Major releases can wait, security updates should be pushed as soon as they can be proven to not break prod.
Notes: Version bump: Eric is a twat so I removed his name from the listed coder team members on the about window.
git push --force
leans back in chair productive day, productive day indeed
git commit -am “Fixed” && git push --forceBTW, I use Arch.
If it was Arch you’d update once every 15 minutes whether anything’s broken or not.
I use Tumbleweed, so I only get updates once/day, twice if something explodes. I used to use Arch, so my update cycle has lengthened from 1-2x/day to 1-2x/week, which is so much better.
gets two update notifications
Ah, must be explosion Wednesday
I really like the tumbleweed method, seems like the best compromise between arch and debian style updates.
I think a lot of what (open)SUSE does is pretty solid. For example, microOS is a fantastic compromise between a stable base and a rolling userspace, and I think a lot of people would do well to switch to it from Leap. I currently use Leap for my NAS, but I do plan to switch to microOS.
That’s advice so smart you’re guaranteed to have massive security holes.
This is AV, and even possible that it is part of definitions (for example some windows file deleted as false positive). You update those daily.
You posted this 14 hours ago, which would have made it 4:30 am in Austin, Texas where Cloudstrike is based. You may have felt the effect on Friday, but it’s extremely likely that the person who made the change did it late on a Thursday.
.
Buy the dip!
.
But probably not immediately, probably slowly over time as contracts come due.
To whom? All their competitors have had incidents like this too.
Huh, so that’s why the office couldn’t order pizza last night lmfao
No one bother to test before deploying to all machines? Nice move.
YOLO 🚀🙈
This outage is probably costing a significant portion of Crowd strike’s market cap. They’re an 80 billion dollar company but this is a multibillion outage.
Someone’s getting fired for this. Massive process failures like this means that it should be some high level managers or the CTO going out.
Puts on Crowdstrike?
They’re already down ~9% today:
finance.yahoo.com/quote/CRWD/
So I think you’re late to the party for puts. Smart money IMO is on a call for a rebound at this point. Perhaps smarter money is looking through companies that may have been overlooked that would be CrowdStrike customers and putting puts on them. The obvious players are airlines, but there could be a ton of smaller cap stocks that outsource their IT to them, like regional trains and whatnot.
Regardless, I don’t gamble w/ options, so I’m staying out. I could probably find a deal, but I have a day job to get to with nearly 100% odds of getting paid.
You’re going to love this: old.reddit.com/…/crowdstrike_is_not_worth_83_bill…
Nice. The first comment is basically saying, “they’re best in class, so they’re worth the premium.” And then the general, “you’ll probably do better by doing the opposite of /r/wallstreetbets” wisdom.
So yeah, if I wanted to gamble, I’d be buying calls for a week or so out when everyone realizes that the recovery was relatively quick and CrowdStrike is still best in class and retained its customers. I think that’s the most likely result here. Switching is expensive for companies like this, and the alternatives aren’t nearly as good.
~20% down in the last month
They’re about where they were back in early June. If they weather this, I don’t see a reason why they wouldn’t jump back to their all-time high in late June. This isn’t a fundamental problem with the solution, it’s a hiccup that, if they can recover quickly, will be just a blip like there was in early June.
I think it’ll get hammered a little more today, and if the response looks good over the weekend, we could see a bump next week. It all depends on how they handle this fiasco this weekend.
The amount of servers running Windows out there is depressing to me
The four multinational corporations I worked at were almost entirely Windows servers with the exception of vendor specific stuff running Linux. Companies REALLY want that support clause in their infrastructure agreement.
I’ve worked as an IT architect at various companies in my career and you can definitely get support contracts for engineering support of RHEL, Ubuntu, SUSE, etc. That isn’t the issue. The issue is that there are a lot of system administrators with “15 years experience in Linux” that have no real experience in Linux. They have experience googling for guides and tutorials while having cobbled together documents of doing various things without understanding what they are really doing.
I can’t tell you how many times I’ve seen an enterprise patch their Linux solutions (if they patched them at all with some ridiculous rubberstamped PO&AM) manually without deploying a repo and updating the repo treating it as you would a WSUS. Hell, I’m pleasantly surprised if I see them joined to a Windows domain (a few times) or an LDAP (once but they didn’t have a trust with the Domain Forest or use sudoer rules…sigh).
Reminds me of this guy I helped a few years ago. His name was Bob, and he was a sysadmin at a predominantly Windows company. The software I was supporting, however, only ran on Linux. So since Bob had been a UNIX admin back in the 80s they picked him to install the software.
But it had been 30 years since he ever touched a CLI. Every time I got on a call with him, I’d have to give him every keystroke one by one, all while listening to him complain about how much he hated it. After three or four calls I just gave up and used the screenshare to do everything myself.
AFAIK he’s still the only Linux “sysadmin” there.
“googling answers”, I feel personally violated.
/s
To be fare, there is not reason to memorize things that you need once or twice. Google is tool, and good for Linux issues. Why debug some issue for few hours, if you can Google resolution in minutes.
I’m not against using Google, stack exhange, man pages, apropos, tldr, etc. but if you’re trying to advertise competence with a skillset but you can’t do the basics and frankly it is still essentially a mystery to you then youre just being dishonest. Sure use all tools available to you though because that’s a good thing to do.
Just because someone breathed air in the same space occasionally over the years where a tool exists does not mean that they can honestly say that those are years of experience with it on a resume or whatever.
Capitalism makes them to.
Agreed. If you are not incompetent, you will remember the stuff that you use often. You will know exactly where to look to refresh your memory for things you use infrequently, and when you do need to look something up, you will understand the solution and why it’s correct. Being good at looking things up, is like half the job.
RedHat, Ubuntu, SUSE - they all exist on support contracts.
I’ve had my PC shut down for updates three times now, while using it as a Jellyfin server from another room. And I’ve only been using it for this purpose for six months or so.
I can’t imagine running anything critical on it.
Windows server, the OS, runs differently from desktop windows. So if you’re using desktop windows and expecting it to run like a server, well, that’s on you. However, I ran windows server 2016 and then 2019 for quite a few years just doing general homelab stuff and it is really a pain compared to Linux which I switched to on my server about a year ago. Server stuff is just way easier on Linux in my experience.
It doesn’t have to, though. Linux manages to do both just fine, with relatively minor compromises.
Expecting an OS to handle keeping software running is not a big ask.
Yup, I use Linux to run a Jellyfin server, as well as a few others things. The only problem is that the CPU I’m using (Ryzen 1st gen) will crash every couple weeks or so (known hardware fault, I never bothered to RMA), but that’s honestly not that bad since I can just walk over and restart it. Before that, it ran happily on an old Phenom II from 2009 for something like 10 years (old PC), and I mostly replaced it because the Ryzen uses a bit less electricity (enough that I used to turn the old PC off at night; this one runs 24/7 as is way more convenient).
So aside from this hardware issue, Linux has been extremely solid. I have a VPS that tunnels traffic into my Jellyfin and other services from outside, and it pretty much never goes down (I guess the host reboots it once a year or something for hardware maintenance). I run updates when I want to (when I remember, which is about monthly), and it only goes down for like 30 sec to reboot after updates are applied.
So yeah, Linux FTW, once it’s set up, it just runs.
You can try to use watchdog to automatically restart on crashes. Or go through RMA.
I could, but it’s a pretty rare nuisance. I’d rather just replace the CPU than go through RMA, a newer gen CPU is quite inexpensive, I could probably get by with a <$100 CPU since anything AM4 should work (I have an X370 with support for 5XXX series CPUs).
I’m personally looking at replacing it with a much lower power chip, like maybe something ARM. I just haven’t found something that would fit well since I need 2-4 SATA (PCIe card could work), 16GB+ RAM, and a relatively strong CPU. I’m hopeful that with ARM Snapdragon chips making their way to laptops and RISC-V getting more available, I’ll find something that’ll fit that niche well. Otherwise, I’ll just upgrade when my wife or I upgrade, which is what I usually do.
4 SATA, 8GB RAM is easy to find. What do you need 16 gigs for? Compiling Gentoo?
Star64 for ARM and Quartz64 for RV.
Running a few services:
You got those backwards.
But yeah, I’ve had my eye on those, but I think 8GB will be a bit limiting, and the CPU in both the Star64 and Quartz64 may be a bit weak. I was about to buy one, then decided to upgrade my desktop PC to a SFF PC, which meant I had some decent hardware lying around. It’s mostly up and running now (still working on Collabora/Only Office), so I’ll be monitoring RAM usage to see if I really need 16GB or if I can get away with 8GB instead, but I have a feeling something like either of those two SBCs will be a bit limiting.
I don’t need all of those services, but I definitely want the first two, and they wouldn’t need to be used at the same time (e.g. if I’m watching a movie, I’m probably not messing with big docs in NextCloud). The last one is very nice to have, but it could be a separate box (I’m gusesing Quartz64 would be plenty, though I may want to play with object detection).
At 8GB it won’t matter going for 16. Even 4 is a lot. It’s not like you watch same video many times.
Wierd. Is it not rsync? I ran mirror for my local network on 1GB SBC.
I was joking about compiling Gentoo. Might need that much RAM here.
So, powerful CPU or hardware encoder.
My brain got SIGBUS.
Not bad decision. Why buy something new, when something old works too.
Maybe. I wish I knew PC-style computers on ARM or RV with upgradable memory. Maybe something from SiFive? Dunno.
I can probably run the CI/CD on my desktop, so if that’s the only bottleneck, I can work around it. Or I can spin up a temporary VPS to handle it. I’ll have a VPS always running to traffic over my VPN, so it could also manage orchestration (sounds like a fun project imo).
It’s just one more thing running. It’s not a ton of resources, but it runs an HTTPS server and more RAM means faster updates. Since I run Tumbleweed, an update could be 1-2GB (everything gets rebuilt when a core dependency gets updated).
I could probably run it on a Raspberry Pi (have one for RetroPie), so I’m not too worried about it.
I probably won’t need that, I’d just store the video in whatever format the cameras send in. I do have a GPU on this PC (nothing special, just a GTX 750ti), but I think I could live without that if I moved to an SBC.
The main thing I’m concerned about it Collabora/OnlyOffice, which is really RAM heavy. I’ll probably only have 1-2 users at a time (me or my wife), and I just think 8GB will be a little lean.
I was super close to getting a Quartz64, but realized upgrading the motherboard and case on my desktop would be about the same price (as Quartz64 + case + PCIe SATA card) and the Quartz64 only has 1x PCIe, so I went for the upgrade (had a Ryzen 1700 w/o motherboard and a couple cases just sitting around). I’d love to go ARM, and a 16GB RAM SBC would probably convince me to switch.
Or motherboards with replacable RAM
Off the car lot, we say ‘request’. But good on you for changing careers.
I really have no idea why you think your choice of wording would be relevant to the discussion in any way, but OK…
.
Wow dude you’re so cool. I bet that made you feel so superior. Everyone on here thinks you are so badass.
I do as well!
Wow and the most predictable reply too? Poor guy. Better luck next time.
Not judging, but why wouldn’t you run Linux for a server?
Because I only have one PC (that I need for work), and I can’t be arsed to cock around with dual boot just to watch movies. Especially when Windows will probably break that at some point.
Can you use Linux as main OS then? What do you need your computer to do?
I need to run windows software that makes other windows software, that will be run on our customers (who pay us quite well) PCs that also run windows.
Plus gaming. I’m not switching my primary box to Linux at any point. If I get a mini server, that will probably ruin Linux.
Mingw, but whatever. Maybe there is somethong mingw can’t do.
Unless it is Apex and some other worst offenders or you use GPU from the only company actively hostile to linux, gaming is fine.
I dunno, but doesn’t like a quarter of the internet kinda run on Azure?
And 60% of Azure is running Linux lol
I guess Spotify was running on the other 40%, as many other services
so 40% of azure crashes a quarter of the internet…
Said another way, 3/4 of the internet isn’t on Unsure cloud blah-blah.
And azure is - shhh - at least partially backed by Linux hosts. Didn’t they buy an AWS clone and forcibly inject it with money like Bobby Brown on a date in the hopes of building AWS better than AWS like they did with nokia? MS could be more protectively diverse than many of its best customers.
Where did you think Microsoft was getting all (hyperbole) of their money from?
I know i was really surprised how many there are. But honestly think of how many companies are using active directory and azure
play stupid games win stupid prizes
A few years ago when my org got the ask to deploy the CS agent in linux production servers and I also saw it getting deployed in thousands of windows and mac desktops all across, the first thought that came to mind was “massive single point of failure and security threat”, as we were putting all the trust in a single relatively small company that will (has?) become the favorite target of all the bad actors across the planet. How long before it gets into trouble, either because if it’s own doing or due to others?
I guess that we now know
No bad actors did this, and security goes in fads. Crowdstrike is king right now, just as McAfee/Trellix was in the past. If you want to run around without edr/xdr software be my guest.
I don’t think anyone is saying that… But picking programs that your company has visibility into is a good idea. We use Wazuh. I get to control when updates are rolled out. It’s not a massive shit show when the vendor rolls out the update globally without sufficient internal testing. I can stagger the rollout as I see fit.
You can do this with CS as well, but the dumbasses where pushing major updates via channel files which aren’t for that. They tried to squeak by without putting out a major update via the sensor updates which you can control. Basically they fucked up their own structure because a bunch of people where complaining and more than likely management got involved and overwrote best practices.
Hmm. Is it safer to have a potentially exploitable agent running as root and listening on a port, than to not have EDR running on a well-secured low-churn enterprise OS - sit down, Ubuntu - adhering to best practice for least access and least-services and good role-sep?
It’s a pickle. I’m gonna go with “maybe don’t lock down your enterprise Linux hard and then open a yawning garage door of a hole right into it” but YMMV.
Reality is, if your users are educated, then your more secure than any edr with dumbass users. But we all know this is a pipe dream.
All of the security vendors do it over enough time. McAfee used to be the king of them.
zdnet.com/…/defective-mcafee-update-causes-worldw…
bleepingcomputer.com/…/trend-micro-antivirus-modi…
techradar.com/…/microsoft-releases-fix-for-botche…
oh joy. can’t wait to have to fix this for all of our clients today…
.
I’m so tired of all the fun…
You’re going to have fun whether you like it or not.
<img alt="" src="https://lemmy.world/pictrs/image/3058b86f-321b-4d4d-a40e-ead7d637617d.jpeg">
(Seemed appropriate lol)
“Today”, right. I wish you a good weekend stranger.
We had a bad CrowdStrike update years ago where their network scanning portion couldn’t handle a load of DNS queries on start up. When asked how we could switch to manual updates we were told that wasn’t possible. So we had to black hole the update endpoint via our firewall, which luckily was separate from their telemetry endpoint. When we were ready to update, we’d have FW rules allowing groups to update in batches. They since changed that but a lot of companies just hand control over to them. They have both a file system and network shim so it can basically intercept **everything **
It’s a fair point but I would rather diversify and also use something that is open / less opaque
ReactOS for the win!
An offline server is a secure server!
Honestly my philosophy these days, when it comes to anything proprietary. They just can’t keep their grubby little fingers off of working software.
At least this time it was an accident.
There is nothing unsafer than local networks.
AV/XDR is not optional even in offline networks. If you don’t have visibility on your network, you are totally screwed.
My company used to use something else but after getting hacked switched to crowdstrike and now this. Hilarious clownery going on. Fingers crossed I’ll be working from home for a few days before anything is fixed.
<img alt="" src="https://lemmy.world/pictrs/image/2b3581a1-27d9-473e-b9b9-864dc2c41ba1.jpeg">
Clownstrike
Crowdshite haha gotem
CrowdCollapse
AWS No!!!
Oh wait it’s not them for once.
TFW the green check is actually correct.
Yeah my plans of going to sleep last night were thoroughly dashed as every single windows server across every datacenter I manage between two countries all cried out at the same time lmao
How many coffee cups have you drank in the last 12 hours?
I work in a data center
I lost count
What was Dracula doing in your data centre?
Because he’s Dracula. He’s twelve million years old.
THE WORMS
Surely Dracula doesn’t use windows.
I work in a datacenter, but no Windows. I slept so well.
Though a couple years back some ransomware that also impacted Linux ran through, but I got to sleep well because it only bit people with easily guessed root passwords. It bit a lot of other departments at the company though.
This time even the Windows folks were spared, because CrowdStrike wasn’t the solution they infested themselves with (they use other providers, who I fully expect to screw up the same way one day).
There was a point where words lost all meaning and I think my heart was one continuous beat for a good hour.
I always wondered who even used windows server given how marginal its marketshare is. Now i know from the news.
Well, I’ve seen some, but they usually don’t have automatic updates and generally do not have access to the Internet.
This is a crowdstrike issue specifically related to the falcon sensor. Happens to affect only windows hosts.
My current company does and I hate it so much. Who even got that idea in the first place? Linux always dominated server-side stuff, no?
You should read the saga of when MS bought Hotmail. The work they had to do to be able to run it on Windows was incredible. It actually helped MS improve their server OS, and it still wasn’t as performance when they switched over.
Yes, but the developers learned on Windows, so they wrote software for Windows.
In university computer science, in the states, MS server was the main server OS that they taught my class during our education.
Microsoft loses money to let the universities and students use and learn MS server for free, or at least they did at the time. This had the effect of making a lot of fresh grad developers more comfortable with using MS server, and I’m sure it led to MS server being used in cases where there were better options.
No, Linux doesn’t now nor has it ever dominated the server space.
Marginal? You must be joking. A vast amount of servers run on Windows Server. Where I work alone we have several hundred and many companies have a similar setup. Statista put the Windows Server OS market share over 70% in 2019. While I find it hard to believe it would be that high, it does clearly indicate it’s most certainly not a marginal percentage.
I’m not getting an account on Statista, and I agree that its marketshare isn’t “marginal” in practice, but something is up with those figures, since overwhelmingly internet hosted services are on top of Linux. Internal servers may be a bit different, but “servers” I’d expect to count internet servers…
It’s stated in the synopsis, below where it says you need to pay for the article. Anyway, it might be true as the hosting servers themselves often host up to hundreds of Windows machines. But it really depends on what is measured and the method used, which we don’t know because who the hell has a statista account anyway.
Most servers aren’t Internet-facing.
There are a ton of Internet facing servers, vast majority of cloud instances, and every cloud provider except Microsoft (and their in house “windows” for azure hosting is somehow different, though they aren’t public about it).
In terms of on premise servers, I’d even say the HPC groups may outnumber internal windows servers. While relatively fewer instances, they all represent racks and racks of servers, and that market is 100% Linux.
I know a couple of retailers and at least two game studios are keeping at scale windows a thing, but Linux mostly dominates my experience of large scale deployment in on premise scale out.
It just seems like Linux is just so likely for scenarios that also have lots of horizontal scaling, it is hard to imagine that despite that windows still being a majority share of the market when all is said and done, when it’s usually deployed in smaller quantities in any given place.
This is a common misconception. Most internet hosted services are behind a Linux box, but that doesn’t mean those services actually run on Linux.
Not too long ago, a lot of Customer Relationship Management (CRM) software ran on MS SQL Server. Businesses made significant investments in software and training, and some of them don’t have the technical, financial, or logistical resources to adapt - momentum keeps them using Windows Server.
For example, small businesses that are physically located in rural areas can’t use cloud based services because rural internet is too slow and unreliable. Its not quite the case that there’s no amount of money you can pay for a good internet connection in rural America, but last time I looked into it, Verizon wanted to charge me $20,000 per mile to run a fiber optic cable from the nearest town to my client’s farm.
It’s only marginal for running custom code. Every large organization has at least a few of them running important out-of-the-box services.
Almost everyone, because the Windows server market share isn’t marginal at all.
Did you feel a great disturbance in the force?
Oh yeah I felt a great disturbance (900 alarms) in the force (Opsgenie)
How’s it going, Obi-Wan?
<img alt="" src="https://sh.itjust.works/pictrs/image/1b860497-8e1f-472a-a124-a2c2b12e9c1f.gif">
Honestly kind of excited for the company blogs to start spitting out their
disaster recoverycrisis management stories.I mean - this is just a giant test of
disaster recoverycrisis management plans. And while there are absolutely real-world consequences to this, the fix almost seems scriptable.If a company uses IPMI (
CalledBranded AMT and sometimes vPro by Intel), and their network is intact/the devices are on their network, they ought to be able to remotely address this.But that’s obviously predicated on them having already deployed/configured the tools.
On desktops, nobody does. Servers, yes, all the time.
Depends on your management solutions. Intel vPro can allow remote access like that on desktops & laptops even if they’re on WiFi and in some cases cellular. It’s gotta be provisioned first though.
Yeah, and no company in my experience bothers provisioning it. The cost of configuring and maintaining it exceeds the cost of handling failure events, even on large scales like this.
VPro is massively a desktop feature. Servers have proper IPMI/iDrac with more features, and VPro fills (part of) that management gap for desktops. It’s pretty cool it’s not spoiled or disabled. Time to reburn all the desktops in east-07? VPro will be the way.
Anyone who starts DR operations due to this did 0 research into the issue. For those running into the news here…
CrowdStrike Blue Screen solution
CrowdStrike blue screen of death error occurred after an update. The CrowdStrike team recommends that you follow these methods to fix the error and restore your Windows computer to normal usage.
No need to roll full backups… As they’ll likely try to update again anyway and bsod again. Caching servers are a bitch…
I think we’re defining disaster differently. This is a disaster. It’s just not one that necessitates restoring from backup.
Disaster recovery is about the plan(s), not necessarily specific actions. I would hope that companies recognize rerolling the server from backup isn’t the only option for every possible problem.
I imagine CrowdStrike pulled the update, but that would be a nightmare of epic dumbness if organizations got trapped in a loop.
I’ve not read a single DR document that says “research potential options”. DR stuff tends to go into play AFTER you’ve done the research that states the system is unrecoverable. You shouldn’t be rolling DR plans here in this case at all as it’s recoverable.
I also would imagine that they’d test updates before rolling them out. But we’re here… I honestly don’t know though. None of the systems under my control use it.
Right, “research potential options” is usually part of Crysis Management, which should precede any application of the DR procedures.
But there’s a wide range for the scope of those procedures, they might go from switching to secondary servers to a full rebuild from data backups on tape. In some cases they might be the best option even if the system is easily recoverable (eg: if the DR procedure is faster than the recovery options).
Just the ‘figuring out what the hell is going on’ phase can take several hours, if you can get the DR system up in less than that it’s certainly a good idea to roll it out. And if it turns out that you can fix the main system with a couple of lines of code that’s great, but noone should be getting chastised for switching the DR system on to keep the business going while the main machines are borked.
That’s a really astute observation - I threw out disaster recovery when I probably ought to have used crisis management instead. Imprecise on my part.
The other commenter on this pointed out that I should have said crisis management rather than disaster recovery, and they’re right - and so were you, but I wasn’t thinking about that this morning.
Nah, it’s fair enough. I’m not trying to start an argument about any of this. But ya gotta talk in terms that the insurance people talk in (because that’s what your c-suite understand it in). If you say DR… and didn’t actually DR… That can cause some auditing problems later. I unfortunately (or fortunately… I dunno) hold the C-suite position in a few companies. DR is a nasty word. Just like “security incident” is a VERY nasty phrase.
Nah… just boot into safemode > cmd prompt: CD C:\Windows\System32\drivers\CrowdStrike
Then: del C-00000291*.sys
Exit/reboot.
The stuff I copied into the end of my comment is direct from CrowdStrike,.
Hm… yeah what I provided worked for us.
Note this is easy enough to do if systems are booting or you dealing with a handful, but if you have hundreds of poorly managed systems, discard and do again.
Yeah I can only imagine trying to walk someone through an offsite system that got bitlocked because you need to get into safe-mode. reimage from scratch might just be a faster process. Assuming that your infrastructure is setup to do it automatically through network.
I’m here right now just to watch it unfold in real time. Unfortunately Reddit is looking juicer on that front.
libreddit.northboot.xyz
.
IPMI is not AMT. AMT/vPro is closed protocol, right? Also people are disabling AMT, because of listed risks, which is too bad; but it’s easier than properly firewalling it.
Better to just say “it lets you bring up the console remotely without windows running, so machines can be fixed by people who don’t have to come into the office”.
Ah, you’re right. A poor turn of phrase.
I meant to say that intel brands their IPMI tools as AMT or vPro. (And completely sidestepped mentioning the numerous issues with AMT, because, well, that’s probably a novel at this point.)
best day ever. the digitards get a wakeup call. how often have been lectured by imbeciles how great whatever dumbo closed source is. “i need photoshop”, “windows powershell and i get work done”, “azure and onedrive and teams…best shit ever”, " go use NT, nobody will use a GNU".
yeah well, i hope every windows user would be kept of the interwebs for a year and mac users just burn in hell right away. lazy scum that justifies shitting on society for their own comfort. while everyone needs a drivers license, dumb fucking parents give tiktok to their kids…idiocracy will have a great election this winter.
So when’s the last time you touched some grass? It’s a lovely day outside. Maybe go to a pet shelter and see some puppies? Are you getting enough fiber? Drinking enough water? Why not call a friend and hang out?
Yeah, I agree with the sentiment, but this is pretty intense.
.
I have a MacBook that runs Linux. Where am I on the shitbird scale?
you are 1337!
Why thank you.
Bold of you to assume this person has friends!
While I get your point on the over reliance on Microsoft, some of us are going to be stuck spending the whole day trying to fix this shit. You could show some compassion.
no. after decades…not anymore. again and again. there is no good excel, apple users are not “educated”. just assholes caring about themselves and avoiding the need to learn. i did not yet hear any valid argument.
why not show compassion for driving bmw series 5 without a drivers license around kindergard?
i’m seriously just done with every windows,android,osx user forever. digital trumps. thats all they are. me. me. me.
So what do I tell the doctors who can’t care for their patients when I start work today? That it’s their fault leadership chose the software they did? Or do I swallow my pride and put the patients before everything else? Personally, I’m going to choose the latter as the patients wellbeing comes before my opinions about my hospitals choice in software.
for one you could tell them your greed and laziness has led to this. when it was clear (windows3.11) that bill gates is a thief (qdos) and crook (mom make that ibm deal) you chose to stick with “easy”. ask the doctors how chosing that path would impact their work.
what needs to happen to make you get you off your high horse and ditch close source? and please dont lecture me on " how hard it is to change"…youve shown that already.
face the consequences of your actions.
See you’re way off the rails now.
Stallman? Is that you? Did you slip your cuffs?
Literally every program you outlined here are not Windows exclusive. If you let people lecture you on this shit that’s on you.
You guys remember that world of warcraft episode of south park?
This is him.
You kinda went off the rails, there.
It’s fun to dunk on the closed source stuff, but this is a release engineering thing that isn’t the fault of a software license.
Render unto Caesar, dude.
It’s a nice rant, but it also combined government regulation and monocultures and indolence. You should cut that up into several different rants, bringing out the proper one in a more focused spiel for a timely and dramatic win. The lack of cohesion also means you’re taking longer to get the rant out, and if it’s too long to hold focus you’ll reduce your points awarded for the dunk.
Otherwise, lots of street-preacher potential. Solid effort.
This is a a ruse to make Work From Home end.
All IT people should go on general strike now.
???
How would this have been prevented by working on site?
A crowd strike, you could call it
This is just blatantly incorrect - 99% of these outages are going to be fixed remotely.
Eh. This particular issue is making machines bluescreen.
Virtualized assets, If there’s a will there’s a way. Physical assets with REALLY nice KVMs… you can probably mount up an ISO to boot into to remove the stupid definitions causing this shit. Everything else? Yeah… you probably need to be there physically to fix it.
But I will note that many companies by policy don’t allow USB insertion… virtually or not. Which will make this considerably harder across the board. I agree that I think the majority could be fixed remotely. I don’t think the “other” categories are only 1%… I think there’s many more systems that probably required physical intervention. And more importantly… it doesn’t matter if it’s 100% or 0.0001%… If that one system is the one that makes the company money… % population doesn’t matter.
Not at my company. We’re all stuck in BSOD boot loops thanks to BitLocker, and our BIOS is password protected by IT. This is going to take weeks for them to manually update, on site, all the computers one by one.
“Never attribute to malice that which can be adequately explained by stupidity.”
Ironic. They did what they are there to protect against. Fucking up everyone’s shit
Maybe centralizing everything onto one company’s shoulders wasn’t such a great idea after all…
Wait, monopolies are bad? This is the first I’ve ever heard of this concept. So much so that I actually coined the term “monopoly” just now to describe it.
Someone should invent a game, that while playing demonstrates how much monopolies suck for everyone involved (except the monopolist)
And make it so you lose friends and family over the course of the 4+ hour game. Also make a thimble to fight over, that would be dope.
Get your filthy fucking paws off my thimble!
I’m sure a game that’s so on the nose with its message could never become a commercialised marketing gimmick that perversely promotes existing monopolies. Capitalists wouldn’t dare.
I mean, I’m sure those companies that have them don’t think so—when they aren’t the cause of muti-industry collapses.
Yes, it’s almost as if there should be laws to prevent that sort of thing. Hmm
Well now that I’ve invented the concept for the first time, we should invent laws about it. We’ll get in early, develop a monopoly on monopoly legislation and steer it so it benefits us.
Wow, monopolies rule!
Crowdstrike is not a monopoly. The problem here was having a single point of failure, using a piece of software that can access the kernel and autoupdate running on every machine in the organization.
At the very least, you should stagger updates. Any change done to a business critical server should be validated first. Automatic updates are a bad idea.
Obviously, crowdstrike messed up, but so did IT departments in every organization that allowed this to happen.
You wildly underestimate most corporate IT security’s obsession with pushing updates to products like this as soon as they release. They also often have the power to make such nonsense the law of the land, regardless of what best practices dictate. Maybe this incident will shed some light on how bad of an idea auto updates are and get C-levels to do something about it, but even if they do, it’ll only last until the next time someone gets compromised by a flaw that was fixed in a dot-release
Monopolies aren’t absolute, ever, but having nearly 25% market share is a problem, and is a sign of an oligopoly. Crowdstrike has outsized power and has posted article after article boasting of its dominant market position for many years running.
I think monopoly-like conditions have become so normalised that people don’t even recognise them for what they are.
The too big to fail philosophy at its finest.
CrowdStrike has a new meaning… literally Crowd Strike.
They virtually blew up airports
Since when has any antivirus ever had the intent of actually protecting against viruses? The entire antivirus market is a scam.
.
Apparently the slow rollout was skipped (on Crowdstrike’s end) for this
That’s true about the test group deployments, but it turned out this one was not an agent update under that control system. It’s a Channel File update that goes out to all endpoints automatically.
Bahaha 😂😂 continue using proprietary software, that’s all you are going to get in addition to privacy issues… Switch to Linux.
Not easy to switch a secured 4,000+ workstation business. Plus, a lot of companies get their support, license, and managed email from one vendor. It’s bundled in such a way that it would cost MORE to deploy Linux. (And that very much on purpose)
It’s entertaining to me that our brand of monopolistic / oligarchic capitalism itself disincentivizes one-time costs that are greatly outweighed by the risk of future occurrences. Even when those one-time costs would result in greater stability and lower prices…and not even on that big of a time horizon. There is an army of developers that would be so motivated to work on a migration project like this. But then I guess execs couldn’t jet set around the world to hang out at the Crowdstrike F1 hospitality tent every weekend.
(Crowd strike also runs on Linux. This could have happened to Linux too)
Crowd can run on linux, but it is running on all Linux machines? I’ve seen support for some RedHat machines, show me if there’s more
No its not running on all Linux machines. Just like its not running on all wondows machines. But the companies who employ it on their employees laptops also run it on their servers. Crowd strike has easily deployed .debs, .rpms, and .tar.gzs, as well as golden images with it already installed. What we experienced yesterday was the minor version of this catastrophe. If the Linux push had been bad, decent chance it would have taken down major internet structure including the DNS servers you typically use to resolve internet addresses. It would seem to a large number of users that the entire internet was down
I legit have never been more happy to be unemployed.
.
The internet is just a way to communicate data. The only people affected by this bug are customers of a Windows based “cybersecurity” company.
Just a little bit of a correction. Crowd strike publishes agents for Windows, Linux, and MacOS. Its just the particular broken agent is for Windows. They had a 1/3 chance of taking down any one of their three client bases
The company is not Windows based, they offer clients and agents for Linux and Mac as well (and there are some scattered reports they fucked up some of their Linux customers like this last month).
The Windows version of their software is what is broken.
Servers on Windows? Even domain controllers can be Linux-based.
Old servers. Also Crowdstrike took down Linux servers a few years ago.
I’m a long-time Samba fan, but even I wouldn’t run them as DCs in a production environment.
I meant sssd, that I’ve seen working as a DC, if my memory serves me right. But I’ve never been the person setting up a domain controller, so.
EDIT: No, it doesn’t serve me right, from quick googling sssd can’t into DC’s. Kurwa.
Bobr.
Sorry.
Are there any 9P fans?
CrowdStrike: It’s Friday, let’s throw it over the wall to production. See you all on Monday!
<img alt="" src="https://sh.itjust.works/pictrs/image/ce10cdca-116b-4061-b6c3-3f49780c0551.jpeg">
^^so ^^hard ^^picking ^^which ^^meme ^^to ^^use
Good choice, tho. Is the image AI?
Not sure, I didn’t make it. Just part of my collection.
Fair enough!
It’s a real photograph from this morning.
When your push to prod on Friday causes a small but measurable drop in global GDP.
Definitely not small, our website is down so we can’t do any business and we’re a huge company. Multiply that by all the companies that are down, lost time on projects, time to get caught up once it’s fixed, it’ll be a huge number in the end.
I know people who work at major corporations who said they were down for a bit, it’s pretty huge.
GDP is typically stated by the year. One or two days lost, even if it was 100% of the GDP for those days, would still be less than 1% of GDP for the year.
Does your web server run windows? Or is it dependent on some systems that run Windows? I would hope nobody’s actually running a web server on Windows these days.
I have a absolutely no idea. Not my area of expertise.
Actually, it may have helped slow climate change a little
The earth is healing 🙏
For part of today
With all the aircraft on the ground, it was probably a noticeable change. Unfortunately, those people are still going to end up flying at some point, so the reduction in CO2 output on Friday will just be made up for over the next few days.
We did it guys! We moved fast AND broke things!
They did it on Thursday. All of SFO was BSODed for me when I got off a plane at SFO Thursday night.
<img alt="" src="https://y.yarn.co/88e625d6-eff8-4658-b67f-49cc5113449e_text.gif">
Was it actually pushed on Friday, or was it a Thursday night (US central / pacific time) push? The fact that this comment is from 9 hours ago suggests that the problem existed by the time work started on Friday, so I wouldn’t count it as a Friday push. (Still, too many pushes happen at a time that’s still technically Thursday on the US west coast, but is already mid-day Friday in Asia).
I’m in Australia so def Friday. Fu crowdstrike.
Seems like you should be more mad at the International Date Line.
Been at work since 5AM… finally finished deleting the C-00000291*.sys file in CrowdStrike directory.
182 machines total. Thankfully the process in of itself takes about 2-3 minutes. For virtual machines, it’s a bit of a pain, at least in this org.
lmao I feel kinda bad for those companies that have 10k+ endpoints to do this to. Eff… that. Lot’s of immediate short term contract hires for that, I imagine.
How do you deal with places with thousands of remote endpoints??
That’s one of those situations where they need to immediately hire local contractors to those remote sites. This outage literally requires touching the equipment. lol
I’d even say, fly out each individual team member to those sites… but even the airports are down.
Call the remote people in, deputize anyone who can work a command line, and prioritize the important stuff.
Can you program some keyboard-presenting device to automate this? Still requires plugging in something of course…what a mess.
Yeah, there are USB sticks that identify as keyboards and run every keystroke saved in a text file on its memory in sequence. Neat stuff. The primary use case is of course corrupting systems or bruteforcing passwords without touching anything… But they work really well for executing scripts semi-automated.
Yep I have one of these, I think it’s called tiny. Very similar to an Arduino, and very easy to program.
I think sysadmins union should be created today
>Make a kernel-level antivirus
>Make it proprietary
>Don’t test updates… for some reason??
I mean I know it’s easy to be critical but this was my exact thought, how the hell didn’t they catch this in testing?
I have had numerous managers tell me there was no time for QA in my storied career. Or documentation. Or backups. Or redundancy. And so on.
Move fast and break things! We need things NOW NOW NOW!
Push that into the technical debt. Then afterwards never pay off the technical debt
Just always make sure you have some evidence of them telling you to skip these.
There’s a reason I still use lots of email in the age of IM. Permanent records, please. I will email a record of in person convos or chats on stuff like this. I do it politely and professionally, but I do it.
Engineering prof in uni was big on journals/log books for cyoa and it’s stuck with me, I write down everything I do during the day, research, findings etc, easily the best bit of advice I ever had.
A lot of people really need to get into the habit of doing this.
“Per our phone conversation earlier, my understanding is that you would like me to deploy the new update without any QA testing. As this may potentially create significant risks for our customers, I just want to confirm that I have correctly understood your instructions before proceeding.”
If they try to call you back and give the instruction over the phone, then just be polite and request that they reply to your email with their confirmation. If they refuse, say “Respectfully, if you don’t feel comfortable giving me this direction in writing, then I don’t feel comfortable doing it,” and then resend your email but this time loop in HR and legal (if you’ve ever actually reached this point, it’s basically down to either them getting rightfully dismissed, or you getting wrongfully dismissed, with receipts).
The issue with this is that a lot of companies have a retention policy that only retains emails for a particular period, after which they’re deleted unless there’s a critical reason why they can’t be (eg to comply with a legal hold). It’s common to see 2, 3 or 5 year retention policies.
Unless their manager works in Boeing.
There’s some holes in our production units
Software holes, right?
…
…software holes, right?
Completely justified reaction. A lot of the time tech companies and IT staff get shit for stuff that, in practice, can be really hard to detect before it happens. There are all kinds of issues that can arise in production that you just can’t test for.
But this… This has no justification. A issue this immediate, this widespread, would have instantly been caught with even the most basic of testing. The fact that it wasn’t raises massive questions about the safety and security of Crowdstrike’s internal processes.
I think when you are this big you need to roll out any updates slowly. Checking along the way they all is good.
The failure here is much more fundamental than that. This isn’t a “no way we could have found this before we went to prod” issue, this is a “five minutes in the lab would have picked it up” issue. We’re not talking about some kind of “Doesn’t print on Tuesdays” kind of problem that’s hard to reproduce or depends on conditions that are hard to replicate in internal testing, which is normally how this sort of thing escapes containment. In this case the entire repro is “Step 1: Push update to any Windows machine. Step 2: THERE IS NO STEP 2”
There’s absolutely no reason this should ever have affected even one single computer outside of Crowdstrike’s test environment, with or without a staged rollout.
God damn this is worse than I thought… This raises further questions… Was there a NO testing at all??
Tested on Windows 10S
My guess is they did testing but the build they tested was not the build released to customers. That could have been because of poor deployment and testing practices, or it could have been malicious.
Such software would be a juicy target for bad actors.
Agreed, this is the most likely sequence of events. I doubt it was malicious, but definitely could have occurred by accident if proper procedures weren’t being followed.
“I ran the update and now shit’s proper fucked”
That would have been sufficient to notice this update’s borked
Yes. And Microsoft’s
How exactly is Microsoft responsible for this? It’s a kernel level driver that intercepts system calls, and the software updated itself.
This software was crashing Linux distros last month too, but that didn’t make headlines because it effected less machines.
My apologies I thought this went out with a MS update
From what I’ve heard, didn’t the issue happen not solely because of CS driver, but because of a MS update that was rolled out at the same time, and the changes the update made caused the CS driver to go haywire? If that’s the case, there’s not much MS or CS could have done to test it beforehand, especially if both updates rolled out at around the same time.
Is there any links to this?
I’ve seen zero suggestion of this in any reporting about the issue. Not saying you’re wrong, but you’re definitely going to need to find some sources.
From what I’ve heard and to play a devil’s advocate, it coincidented with Microsoft pushing out a security update at basically the same time, that caused the issue. So it’s possible that they didn’t have a way how to test it properly, because they didn’t have the update at hand before it rolled out. So, the fault wasn’t only in a bug in the CS driver, but in the driver interaction with the new win update - which they didn’t have.
How sure are you about that? Microsoft very dependably releases updates on the second Tuesday of the month, and their release notes show if updates are pushed out of schedule. Their last update was on schedule, July 9th.
I’m not. I vaguely remember seeing it in some posts and comments, and it would explain it pretty well, so I kind of took it as a likely outcome. In hindsight, You are right, I shouldnt have been spreading hearsay. Thanks for the wakeup call, honestly!
You left out > Profit
Oh… Wait…Hang on a sec.
Lots of security systems are kernel level (at least partially) this includes SELinux and AppArmor by the way. It’s a necessity for these things to actually be effective.
You missed most important line:
You left out
>Pushed a new release on a Friday
So that’s why my work laptop is down for the count today. I’m even getting that same error as the thumbnail picture
Yep, this is the stupid timeline. Y2K happening to to the nuances of calendar systems might have sounded dumb at the time, but it doesn’t now. Y2K happening because of some unknown contractor’s YOLO Friday update definitely is.
I picked the right week to be on PTO hahaha
.
Think of it as ClownStrike, they will be known as a bunch of clowns after this.
Bomb Carrier: “I’m going A”
Random Teammate: “Okay, everyone rush B!”
This is why you create restore points if using windows.
Those things never worked for me… Problems always persisted or it failed to apply the restore point. This is from the XP and Windows 7 days, never bothered with those again. To Microsoft’s credit, both W7 and W10 were a lot more stable negating the need for it.
I can’t say about XP or 7 but they’ve definitely saved my bacon on Win10 before on my home system. And the company I work for has them automatically created and it made dealing with the problem much easier as there was a restore point right before the crowdstrike update. No messing around with the file system drivers needed.
I’d really recommend at least creating one at a state when your computer is working ok, it doesn’t hurt anything even if it doesn’t work for you for whatever reason. It’s just important to understand that it’s not a cure all, it’s only designed to help with certain issues (primarily botched updates and file system trouble).
A lot of people I work with were affected, I wasn’t one of them. I had assumed it was because I put my machine to sleep yesterday (and every other day this week) and just woke it up after booting it. I assumed it was an on startup thing and that’s why I didn’t have it.
Our IT provider already broke EVERYTHING earlier this month when they remote installed" Nexthink Collector" which forced a 30+ minute CHKDSK on every boot for EVERYONE, until they rolled out a fix (which they were at least able to do remotely), and I didn’t want to have to deal with that the week before I go in leave.
But it sounds like it even happened to running systems so now I don’t know why I wasn’t affected, unless it’s a windows 10 only thing?
Our IT have had some grief lately, but at least they specified Intel 12th gen on our latest CAD machines, rather than 13th or 14th, so they’ve got at least one win.
Your computer was likely not powered on during the time window between the fucked update pushing out and when they stopped pushing it out.
That makes sense, although I must have just missed it, for people I work with to catch it.
It’s Russia, or Iran or China or even our “ally” Saudi Arabia. So really, it’s time to reset the clock to pre 1989. Cut Russia and China off completely, no investment, no internet, no students no tourist nothing. These people mean and are continually doing us harm and we still plod along and some unscrupulous types become agents for personal profit. Enough.
It was a bad update…
Let’s ignore that it was an American company taking down EVERYONE’S stuff, I guess
I mean, I’m not completely against that… but Crowdstrike is an American company. Did you comment on the wrong post?
I was quite surprised when I heard the news. I had been working for hours on my PC without any issues. It pays off not to use Windows.
It’s not a flaw with Windows causing this.
The issue is with a widely used third party security software that installs as a kernel level driver. It had an auto update that causes bluescreening moments after booting into the OS.
This same software is available for Linux and Mac, and had similar issues with specific Linux distros a month ago. It just didn’t get reported on because it didn’t have as wide of an impact.
Because most data center admins using linux are not so stupid to subscribe to remote updates from a third party. Linux issues happen when critical package vulnerabilities make it into the repo.
Tell me how you haven’t worked as a sysadmin again.
This wasn’t some switchable feature. The only way I’ve seen to stop this software from auto updating (per some comments on Hacker News/Y Combinator) as it chooses is by blocking the update servers at the firewall or through DNS black holing.
And yes, they chose to use this software. Look. Crowdstrike bought a fucking SuperBowl ad, a bunch of executives drank the kool aid, and a lot of tech departments were told that they’d be rolling this software out. That’s just how corporate IT works sometimes.
I was saying:
Your response is not related in any way to that. If a third party software - running on system rights - forces auto-updates, that’s called a “rootkit” and any sane admin would refuse to install such a package.
Competent here also meaning “if the upper management refuses to listen to my advice, I leave because I have other options”. People who implement stupid policies - and especially technological solutions - against their principles are a cancer to democracy. Those are the people that enable tech-illiterate morons to implement totalitarian regimes.
They skimp on QA?
Still a MS issue. Both testing and rollout procedures were inadequate
But MS had nothing to do with both the testing and rollout?
It’s a broken 3rd party component. Croudstrikes testing and rollout procedures were inadequate.
How is it Microsoft’s fault when a third party software bricked the OS?
My Windows gaming PC is completely fine right now, because I don’t use crowd strike. Microsoft didn’t have anything to do with crowd strikes’ rollout or support.
I love Linux and use it as my daily driver for everything besides some online games. There are plenty of legitimate reasons to criticize Microsoft and Windows, but crowd strike breaking stuff isn’t one of them, at least in my opinion.
My bad i thought this went out with a MS update
Yeah, my work also survived perfectly fine.
It pays off to use Windows and Microsoft Defender for Endpoint and not Crowdstrike.
www.theregister.com has a series of articles on what’s going on technically.
Latest advice…
Boot Windows into Safe Mode or WRE.
Go to C:\Windows\System32\drivers\CrowdStrike
Locate and delete file matching “C-00000291*.sys”
Boot normally.
Working on our units. But only works if we are able to launch command prompt from the recovery menu. Otherwise we are getting a F8 prompt and cannot start.
Bootable USB stick?
Yeah some 95% of our end user devices (>8000) have the F8 prompt. Logistics is losing their minds about the prospect of sending recovery USBs to roughly a thousand locations across NA.
Yeah I had to do this with all my machines this morning. Worked.
For a second I thought this was going to say “go to C:\Windows\System32 and delete it.”
I’ve been on the internet too long lol.
crowdstrike sent a corrupt file with a software update for windows servers. this caused a blue screen of death on all the windows servers globally for crowdstrike clients causing that blue screen of death. even people in my company. luckily i shut off my computer at the end of the day and missed the update. It’s not an OTA fix. they have to go into every data center and manually fix all the computer servers. some of these severs have encryption. I see a very big lawsuit coming…
I don’t see how they can recover from that. They will get lawsuits from all around the world.
I’m never financially recovering from this. - George Kurtz
Jesus christ, you would think that (a) the company would have safeguards in place and (b) businesses using the product would do better due diligence. Goes to show thwre are no grown ups in the room inside these massive corporations that rule every aspect of our lives.
I’m calling it now. In the future there will be some software update for your electric car, and due to some jackass, millions of cars will end up getting bricked in the middle of the road where they have to manually be rebooted.
We’re already halfway there! reddit.com/…/cant_drive_your_car_due_to_update/#l…
Laid off one too many persons, finance bros taking over
I work for one of these behemoths, and there are a lot of adults in the room. When we began our transition off the prior, well known corporate AV, I never even heard of crowd strike.
The adults were asking reasonable questions: why such an aggressive migration timeline? Why can’t we have our vendor recommended exclusion lists applied? Why does this need to be installed here when previously agentless technologies was sufficient? Why is crowd strike spending monies on a Superbowl ad instead of investing back into the technology?
Either something fucky is a foot, as in this was mandated to our higher ups to m make the switch (why?), or, as is typically the case, the decision was made already and this ‘due diligence’ is all window dressing to CYA.
Who gives a shit about fines on SLAs if your vendor is going to foot the bill.
Insane that these people are the ones making the decisions
As someone who works in offensive Cybersecurity doing Red Teamings, where most of my job is to bypass and evade such solutions, I can say that bypassing agent less technologies is so much easier than agented ones. While you can access most of the logs remotely, having an agent helps you extremely with catching 0-day malware, since you can scan memory (that one is a bitch to bypass and usually how we get caught), or hook syscalls which you can then correlate.
Oh, an unknown unsigned process just called RWX memory allocation, loaded a crypto binary, and spawned a thread in another process that’s trying to execute it? Better scan that memory and see what it’s up to. That is something you cannot do remotely.
Do they not have IPMI/BMC for the servers? Usually you can access KVM over IP and remotely power-off/power-on/reboot servers without having to physically be there. KVM over IP shows the video output of the system so you can use it to enter the UEFI, boot in safe/recovery mode, etc.
I’ve got IPMI on my home server and I’m just some random guy on the internet, so I’d be surprised if a data center didn’t.
Then you’d be surprised.
I feel sorry for sys admins that have to administer servers in a remote data center and don’t have KVM over IP.
Sometimes there are options that are reasonable for individual users that don’t scale well to enterprise environments.
Also, the effectively gives attackers a secondary attack surface in addition to the normal remote access technologies that require the machine to be up and running to work.
I don’t know many individual users that use IPMI. I only really see it used by hosting (and other) companies in data centers.
IPMI is usually locked down and only accessible on a management VLAN, and also often IP locked, plus the system itself would have a password.
.
Webroot had something similar ish earlier this year. Such a pain.
Stop running production services on M$. There is a better backend OS.
There’s a better frontend OS
Doesn’t mean people want to go away from what they know
There’s a shit ton more reasons than that, but in short: I highly doubt anyone suggesting a company just up and leave the MS ecosystem has spent any considerable amount of time in a sysadmin position.
You’ll find xp in use because they don’t want to pay for a new system
And Linux/BSD is way more expensive because not as many people are familiar with it
The issue was caused by a third-party vendor, though. A similar issue could have happened on other OSes too. There’s relatively intrusive endpoint security systems for MacOS and Linux too.
That’s the annoying thing here. Everyone, particularly Lemmy where everyone runs Linux and FOSS, thinks this is a Microsoft/Windows issue. It’s not, it’s a Crowdstrike issue.
Everyone, particularly Lemmy where everyone runs Linux and FOSS, knows it is a Crowdstrike issue.
More than that: it’s an IT security and infrastructure admin issue. How was this 3rd party software update allowed to go out to so many systems to break them all at once with no one testing it?
Bingo. I work for a small software company, so I expect shit like this to go out to production every so often and cause trouble for our couple tens of thousands of clients… But I can’t fathom how any company with worldwide reach can let it happen…
That’s because cloudstrike likely has significantly worse leadership compared to your company.
They have a massive business development budget though.
From what I understand, Crowdstrike doesn’t have built in functionality for that.
One admin was saying that they had to figure out which IPs were the update server vs the rest of the functionality servers, block the update server at the company firewall, and then set up special rules to let the traffic through to batches of their machines.
So… yeah. Lot of work, especially if you’re somewhere where the sysadmin and firewall duties are split across teams. Or if you’re somewhere that is understaffed and overworked. Spend time putting out fires, or jerry-rigging a custom way to do staggered updates on a piece of software that runs largely as a black box?
Edit: re-read your comment. My bad, I think you meant it was a failure of that on CrowdStrike’s end. Yeah, absolutely.
It’s a MS process issue. This is a testing failure and a rollout failure
Windows is imfamous for a do-it-yourself install process, they are likely using their own deployment tools. If anything, criticize them for not helping the update process at all.
This had nothing to do with MS, other than their OS being impacted. Not their software that broke, not an update pushed out by their update system. This is an entirely third party piece of software that installs at the kernel level, deeper than MS could reasonably police, even it somehow was their responsibility.
Thid same piece of software was crashing certain Linux distros last month, but it didn’t make headlines due to the limited scope.
My bad i thought this went out with a MS update
Microsoft would never push an update on a Friday. They usually push their major patches on Tuesdays, unless there’s something that’s extremely important and can’t wait.
Its an snakeoil issue.
Many news sources said it’s a “Microsoft update”, so it’s understandable that people are confused.
Also, there was an Azure outage yesterday.
Crowdstrike did the same to Linux servers previously.
I’m used to IT doing a lot of their work on the weekends as to not impact operations.
Good ol microsloth
As much as it pains me to say it, it’s not really Microsoft at fault here, it’s CrowdStrike.
MS should have done testing as well. They can’t dodge this
Oh for their cloud services absolutely, you’re right.
I’m so exhausted… This is madness. As a Linux user I’ve busy all day telling people with bricked PCs that Linux is better but there are just so many. It never ends. I think this is outage is going to keep me busy all weekend.
You’re comment I came looking for. You get a standing ovation or something.
A month or so ago a crowdstrike update was breaking some of our Linux vms with newer kernels. So it’s not just the os.
How? I’m really curious to learn.
I don’t know how on either one. I just know it happened.
Crowdstrike bricked networking on our linuxes for quite a few versions.
This isn’t really a Windows vs Linux issue as far as I’m aware. It was a bad driver update made by a third party. I don’t see why Linux couldn’t suffer from the same kind of issue.
We should dunk on Windows for Windows specific flaws. Like how Windows won’t let me reinstall a corrupted Windows Store library file because admins can’t be trusted to manage Microsoft components on their own machine.
I am no expert. But afaik drivers normally are integrated into the kernel and intensively tested by several parties before getting onto your computer. Only for proprietary drivers this would be problematic under Linux.
Crowdstrike by default loads its own kernel modules on linux as well, not much different from how it works under Windows.
What are you, an apostle? Lol. This issue affects Windows, but it’s not a Windows issue. It’s wholly on CrowdStrike for a malformed driver update. This could happen to Linux just as easily given how CS operates. I like Linux too, but this isn’t the battle.
🙄 and then everyone clapped
Yeah it’s all fun and games until you actually convince someone and then you gotta explain how a bootloader works to someone who still calls their browser “Google”
Why do people run windows servers when Linux exists, it’s literally a no brainer.
Because all software runs from Linux right…
It could if more people just used Linux
Servers weren’t much of a problem, they’re mostly virtual and could be just restored from a backup. The several hundred workstations were a problem. They needed a physical touch. All are encrypted with BitLocker, requiring passkeys stored in AD. Over half are laptops. Most of those don’t have wired ethernet ports, and an account with local admin rights hasn’t logged in since the day they were imaged. Throw in a proper LAPS config, where randomly generated passwords of three dozen characters in length are also stored in AD…
… Yeah, today was a bad day.
Are you a Linux user?
Hey everyone, shut up! This guy is a Linux user and he’s here to tell us about using Linux.
Look! We found the anti anti-microsoft user in their natural habitat of talking shit on social media. They are from the same family bootlickers and related to the Tossaladers. Don’t mention you are an alternative OS person around them or they may go into a blind rage.
Linux users and vegetarians. Neither can shut the fuck up. Both have made it their identity.
My last companyoffered apps as either hosted or on-prem. Once they decided the on-prem version had to be Windows for our customer base, it made sense to have one build, one installer. I’m very happy not to be there today.
My current employer is all Linux servers and Engineers use Mac laptops. The only ones affected were Management and HR, LoL. Back of the line for you, we have customers to help!
No brainer… Blames windows… For a 3rd party issue… The same 3rd party that’s done the same thing here to Linux recently… No brainer achieved.
They run Windows and all this third party software because they would rather pay subscriptions and give up control of their business than retain skilled staff. It has nothing todo with Linux vs Windows. Linux won’t stop doors falling off Boeing planes. It is the myopia of modern business culture.
I built a home virtual server host on Proxmox. It destroyed itself 3 times in 6 months. I gave up and installed server 2019 with HyperV. Has been rock solid for years.
lol
<img alt="" src="https://lemmy.world/pictrs/image/b9db4edd-aa39-4133-a4df-6c1d340f9323.png">
too bad me posting this will bump the comment count though. maybe we should try to keep the vote count to 404
I can only see 368 comments rn, there must be some weird-ass puritan server blocking .ml users. It’s not beehaw as I can see comments from there.
I can only conclude that it is probably some liberals trying to block “Tankies” and no comment of value was lost.
Meanwhile Kaspersky: *thinks if so incompetent people can even make antivirus at all*
Never trust a texan
Totally Texas!
To be fair Austin is the least Texan of Texas
Is it still at all Austiney though? With all the companies moving to Austin, I wonder how much of the original Austin is left.
That’s my point, also same with Salt Lake City Utah
This is proof you shouldn’t invest everything in one technology. I won’t say everyone should change to Linux because it isn’t immune to this, but we need to push companies to support several OS
The issue here is kernel level applications that can brick a box. Anti viruses compete for resources, no one should run 2 at once
That’s why I run 3 at once…
4 for the win!
Linux and Mac just got free advertisment.
The words ‘Mac’ and ‘free’ aren’t allowed in the same sentence.
Also, enterprise infrastructure running on a Mac? It’s something I’ve never heard of in over a decade and a half of working in tech. And now I’m curious. Is it a thing?
I’ve never heard of Macs running embedded systems - I think that would be a pretty crazy waste of money - but Mac OS Server was a thing for years. My college campus was all Mac in the G4 iMac days, running MacOS Server to administer the network. As far as I understand it was really solid and capable, but I guess it didn’t really fit Apples focus as their market moved from industry professionals to consumers, and they killed it.
Depending on what your definition of “enterprise” is, I’ve attended what was at the time a fairly large and prestigious art school that ran everything on Macs.
They even preferred that we didn’t bring windows laptops, although after some… rather intense protests by pretty much anyone under 25 we did get to bring our own peripherals.
Edit: I’ll also add that outside the shitty keyboards and mice, the server system they had set up with our accounts on etc was completely fine.
Never had a single issue with it and it was my first ever touching a Mac.
When you say ran everything, what kinda stuff?
This is almost 20 years ago today, so my memory is a bit hazy, but basically each student had an account with a certain amount of server space. I can’t remember the size, but given the amount of digital files we produced it would’ve been at minimum 500GB+/student. We could also “see” the account folder for everyone else in our class for file sharing and stuff.
There were also accounts/folders for each teacher which were used to turn in the primary copy of whatever assignment we had done if it was in digital form. Physical art were scanned or photographed also, as a sort of backup. We were also required to back every project up via USB sticks, ofc.
There was also a rack with individual docks for each digital camera that they had which allowed us to get our photographs transferred to our own folders. Since we could access those files from our accounts it also was a part of that server system.
There were also several networked and customised Macs used for single tasks, like larger printing projects and also for an airgapped paintgun for a lack of a better description. We avoided having to wear masks when we printed large sheets in single colours with it, for example. I have no idea what software that thing used, I think I used it like once or twice.
Now, I’ll freely admit that I haven’t touched a Mac since I left that school, and I’ve never had any interest in them whatsoever, so I don’t know what they used or if it even exists anymore. Someone with more knowhow maybe does?
I do remember them specifically (proudly) telling us it all ran on Macs, otherwise I probably wouldn’t have any reason to believe so. The “server room” was basically what looked like a glorified closet with a rack and a couple of Macs that didn’t look like the ones we students used. This was just before the all-in-one models were introduced, iirc.
Heard linux systems had a similar issue a few months ago
Yeah the more I read it seems some crucial security software deployed bad patch.
I’m sure whatever OS would dominate would face widespread issues just by the numbers.
But to be fair it’s fun to make fun of Windows/MSFT :p
Some intern is getting their ass beat right now, never release into prod without extensive test.
It’s likely not an intern’s fault. Likely a C suite not authorizing the testing infrastructures requested by the developers and sysops people.
If an intern can release to prod without extensive testing there are bigger issues.
Given the scope of the potential impact, if anyone can release to prod and have that deploy to all customers without some form of a canary release strategy, then there are still issues.
<img alt="" src="https://lemmy.ca/pictrs/image/94996946-b202-49b0-b307-ce38639ad900.jpeg">
Everyone is assuming it’s some intern pushing a release out accidentally or a lack of QA but Microsoft also pushed out July security updates that have been causing bsods on the 9th(?). These aren’t optional either.
What’s the likelihood that the CS file was tested on devices that hadn’t got the latest windows security update and it was an unholy union of both those things that’s caused this meltdown. The timelines do potentially line up when you consider your average agile delivery cadence.
I don’t think so. I do updates every two months so I haven’t updated Windows at all in July and it still crashed my servers
Microsoft installs security updates automatically.
Not on any of my servers. All windows updates have to be manually approved installed from the local WSUS server.
Windows moment 🤣
I see a lot of hate ITT on kernel-level EDRs, which I wouldn’t say they deserve. Sure, for your own use, an AV is sufficient and you don’t need an EDR, but they make a world of difference. I work in cybersecurity doing Red Teamings, so my job is mostly about bypassing such solutions and making malware/actions within the network that avoids being detected by it as much as possible, and ever since EDRs started getting popular, my job got several leagues harder.
The advantage of EDRs in comparison to AVs is that they can catch 0-days. AV will just look for signatures, a known pieces or snippets of malware code. EDR, on the other hand, looks for sequences of actions a process does, by scanning memory, logs and hooking syscalls. So, if for example you would make an entirely custom program that allocates memory as Read-Write-Execute, then load a crypto dll, unencrypt something into such memory, and then call a thread spawn syscall to spawn a thread on another process that runs it, and EDR would correlate such actions and get suspicious, while for regular AV, the code would probably look ok. Some EDRs even watch network packets and can catch suspicious communication, such as port scanning, large data extraction, or C2 communication.
Sure, in an ideal world, you would have users that never run malware, and network that is impenetrable. But you still get at avarage few % of people running random binaries that came from phishing attempts, or around 50% people that fall for vishing attacks in your company. Having an EDR increases your chances to avoid such attack almost exponentionally, and I would say that the advantage it gives to EDRs that they are kernel-level is well worth it.
I’m not defending CrowdStrike, they did mess up to the point where I bet that the amount of damages they caused worldwide is nowhere near the amount damages all cyberattacks they prevented would cause in total. But hating on kernel-level EDRs in general isn’t warranted here.
Kernel-level anti-cheat, on the other hand, can go burn in hell, and I hope that something similar will eventually happen with one of them. Fuck kernel level anti-cheats.
The problem here isn’t if you should run EDR or not it’s that people need to take the risk and responsibilities seriously and the cure needs to to be better than the disease.
If you need to hand remote kernel level access over to a company it’s in you to make sure they have the security, QA and basic competency to shoulder that responsibility.
And when it comes out that they don’t even run or verify their code before deploying it to millions of machines all at once, it’s on you for buying not vetting them.
Just like users should check files and where they come from before running them IT professionals need to do the same.