from Stopthatgirl7@lemmy.world to technology@lemmy.world on 26 Oct 2024 22:39
https://lemmy.world/post/21301373
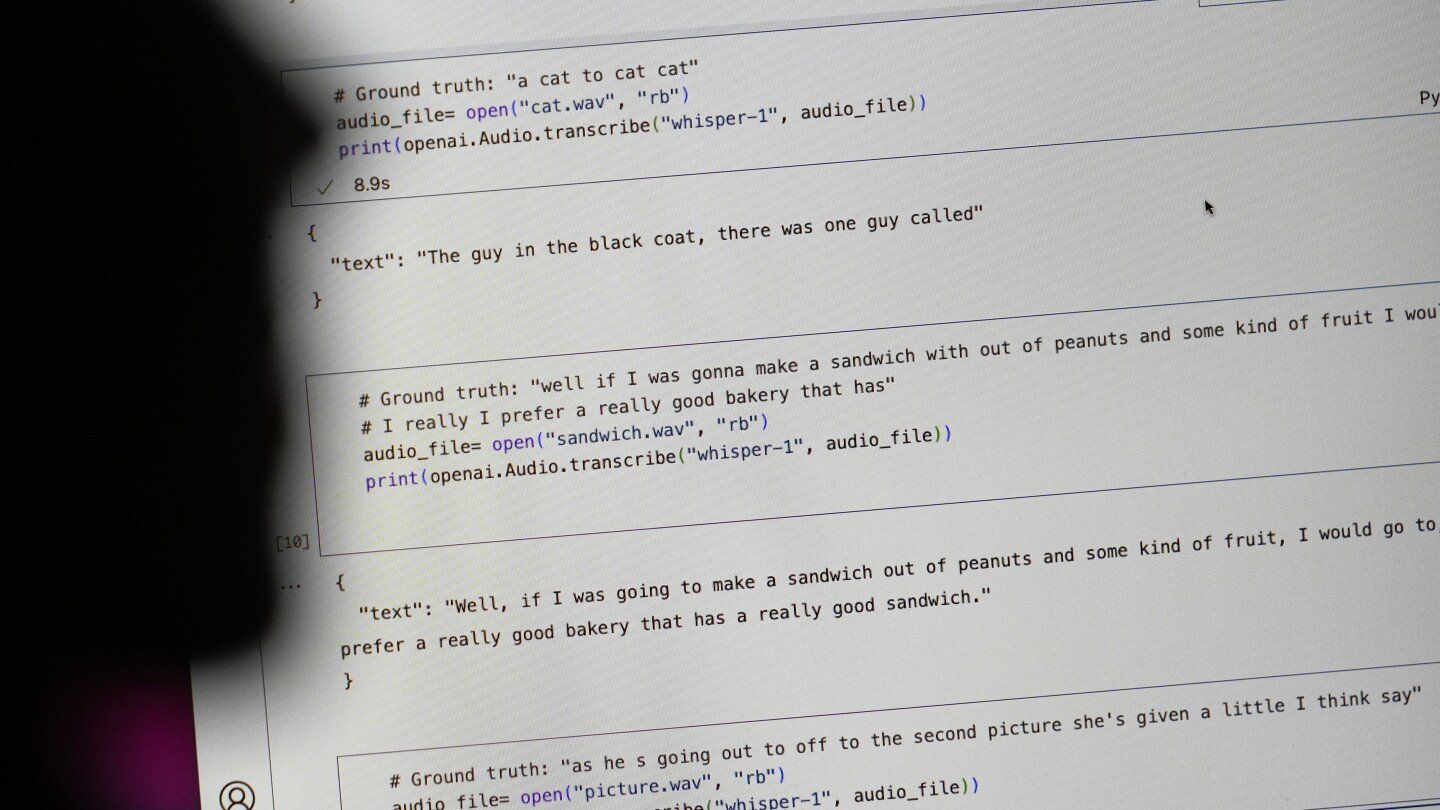
Tech behemoth OpenAI has touted its artificial intelligence-powered transcription tool Whisper as having near “human level robustness and accuracy.”
But Whisper has a major flaw: It is prone to making up chunks of text or even entire sentences, according to interviews with more than a dozen software engineers, developers and academic researchers. Those experts said some of the invented text — known in the industry as hallucinations — can include racial commentary, violent rhetoric and even imagined medical treatments.
Experts said that such fabrications are problematic because Whisper is being used in a slew of industries worldwide to translate and transcribe interviews, generate text in popular consumer technologies and create subtitles for videos.
More concerning, they said, is a rush by medical centers to utilize Whisper-based tools to transcribe patients’ consultations with doctors, despite OpenAI’ s warnings that the tool should not be used in “high-risk domains.”
threaded - newest
Oh word?
AI does not mean Artificial Intelligence, it means Assumed Intelligence.
LLMs in medicine. What could go wrong?
Whisper isn’t a large language model.
It’s a speech to text (STT) model.
Which has the same concept as the LLM under the hood, hasn’t it?
This isn’t a Large Language Model, it’s a Chonky Linguistic Algorithm.
Some examples
Wow, that’s bad. I thought it would be more of a “confusing a sentence for a similar sounding one” type thing but from the above and the article it’s just generating semi-believable text and sticking them into the transcriptions.
It’s actually extremely good at figuring out confusing text. It gets weird when the audio quality is bad.
I use it for generating subs for obscure movies.
No one is good with bad audio. My wife did some transcription work for a little while, it can be pretty painful, especially for doctors, and all the medical terms.
Sounds less like transcribing word for word, and more like attempting to summarize and parse meaning on the fly. AIS have notoriously little grasp on reasoning and logic, so it’s interesting how the output holds up in a court of law.
This one was wild:
From picking up and object to mass murder lmao. Not even close!
But it gets the spirit right
/s
Microsoft teams has some automatic transcript capabilities that are so hilariously bad, it’s hard to believe Microsoft released it.
I guess they use the same service.
It’s super hit or miss, odds are it’s using azure though and not just running a model locally.
The last transcript I’ve seen it guessed the wrong language and literally didn’t get one word right.
Why is generative AI even needed for audio transcription? We’ve had decent voice recognition tools for years even on cheap consumer grade stuff.
We also used to have decent web searches!
Because with normal algorithms you have someone to blame.
AI is a trick to hide when you steer the results the way you want.
Whisper really is a lot better when it works, and it’s free. The problem is that it refuses to produce gibberish or give up when it doesn’t work. You’ll always need an editor.
The toaster oven I just invented works much better than a traditional one. It reheats French fries perfectly, you can dehydrate in it, makes succulent roasted chicken, and about 2.5% of the time it burns down your house. You’ll always need to keep an eye on it to make sure that doesn’t happen. Remember though, much better than a traditional one.
Can I try the chicken before I make a decision?
You need an editor for traditional transcription tools too :) and it’s A LOT more work. They don’t even do punctuation or names.
This definition of “better” feels like claiming that a Beeper that’s constantly hooked to power is the perfect alarm because it warns you every time someone is trying to break in - while entirely ignoring that it is just constantly blaring.
I use it for generating subtitles. It figures out context, it ignores stuttering, it does punctuation etc. It’s really is just better. With clean audio it transcribes like a human does.
It does better than other techniques with dirty audio, but when it fails it fails weird, which is the big issue here.
Because AI!
No, we really haven’t had on-device voice recognition that meets any definition of “decent”. Anything reasonable phones out to “the cloud” for decent voice recognition.
So? I’d rather have my software talk to a server than be downright wrong just so another business can climb onto the AI bandwagon.
You can’t do that with personal information like the ones doctors needs transcribed. It has to be local.
Reality is more nuanced than this. You can absolutely be HIPAA compliant while using “cloud” servers as long as they are sufficiently isolated and secured. The requirements are definitely insufficient to protect your data from a Motivated State Actor™ but they are good enough to keep your data away from an abusive family member or crazy ex. I have worked on systems that handle patient data as well as other systems with restrictions I can’t discuss and I can assure you patient data is much easier to move around and handle compared to state secrets.
Edit: funny story, I just got back from a doctor appointment where they asked me to sign a consent form for recording and transcription of the visit by a computer system. It’s definitely happening, in practice.
I've read that this is only going to continue to happen (and get worse) because we're basically out of human-generated training data that's publicly available on the internet, so models are being trained on content generated by other models. They literally make shit up constantly, and every generation gets dumber and dumber until they can't even stay on topic or complete a coherent sentence anymore.
Edit: Here's the post I was reading, written by Ed Zitron. It's pretty well written and thoughtful, though it is an opinion article from some guy's blog at the end of the day. Also, by "generation," I mean generations of AI, not generations of people.
Odd that GPT (and of course all the LLMs too) only got better so far…
The architecture changed, there is still progress to be made there. But LLMs will forever be stuck in 2021, all data afterwards is tainted. Not a lot has been added.
In fact, Whisper was developed to transcribe videos for more training data, because they ran out of text data. These bad transcriptions are in newer models.
I know how to make the company prioritize it: make Whisper illegal to use (or even promote) until a certain threshold of accuracy is met. This software is absolute garbage at best, and a genuine hazard at worst.
Lame, ineffective “warnings” serve no purpose but to cover OpenAIs ass. Hit them in the wallet, and they’ll pay attention.
Rather than making it illegal to use, people need to use these tools responsibly. If any of these companies are using almost any kind of AI/machine learning they need to include a human in the loop that can verify that it’s working correctly. That way if it starts hallucinating things that were never said, it can be caught and corrected.
I’ve found that Whisper generally does a better job at translating/transcribing audio than other open source tools out there, so it’s not garbage… But it absolutely is a hazard if you’re trying to rely solely on it for official documents (or legal issues).
As far as promotion goes… It’s open source software, it’s not being sold.
Have you met people…?
I have an even better idea: make tool creators and / or CEO of the company, using the tool, liable for all tool’s mistakes and hallucinations.
It is illegal to use in the EU for anything even remotely sensitive. Like, if you subtitle a movie with it and it messes up noone cares, your problem, if you’re doing anything that has any legal implications, from college applications over job interviews to court proceedings, they’ll nail you to the cross. For AI to be used in such domains it has to be certified and AIs certified for even a subset of these things plainly don’t exist.
It’s like with self-driving cars: What OpenAI is producing is pretty much on the level of Tesla’s “full self driving”. It’s not even waymo who have proper autonomy tech certified to operate in a limited area in a benevolent (to venture capital) jurisdiction (some municipality or the other). Wake me when it gets actual approval from actual regulatory bodies actively trying to break it.
maybe that’s just the ai’s internal monologue leaking through?
As someone who uses Whisper fairly often, it’s obvious that they’ve trained off of a bunch of YouTube videos.
Most of the time it’s very accurate, but there have definitely been a few times in long transcription sessions where it will randomly hallucinate that someone is saying “Don’t forget to like and subscribe!” When nothing was said anywhere near that.
That’s hilarious. I just love how AI is basically like a 6-year-old who weaves his favorite new expressions into everything without fully understanding what they mean.
A few months back my GP asked if they could use a transcription thing they were trialling during my consult.
He seemed shocked when I declined.
I just don’t understand why anyone would actually want that?
I want my doctor to listen to what I tell him, and I don’t really want what I say to be used for any other purpose, because no other purpose would be to my benefit.
Next week they’ll be adding to share “basic characteristics” about me with third party “wellness partners”.
Ml is currently best used as a tool for helping a real human do work. It has to be managed and governed and checked after. It’s still capable of amplifying the amount of work we can do, But it’s kind of like having to have an architect look after engineering work, you can’t just pass the buck and pretend that it’s going to be fine.